Faire du OCR sur l'iPhone? Yes, we can!
Qu’est ce que l’OCR? Très simple c’est du Optical Character Recognition. Et là tout le monde: du quoi? En français, c’est de la Reconnaissance Optique de Caractères En gros, on prend une image sur laquelle il y a du texte et l’OCR va se charger d’extraire le texte de l’image par différents algorithmes et retourner ce texte sous forme de chaîne de caractères. En résumé très résumé *.png -> *.txt.
Trop fort! Je veux sur l’iPhone
Je me suis dit que ça pouvait être rigolo d’avoir un OCR sur l’iPhone. On prend du texte en photo et le texte est extrait. L’OCR n’était pas une idée super nouvelle: ça a commencé en 1929, il y a donc pas mal de logiciels et libraires qui existent déjà pour faire du OCR. Ici, on va s’intéresser à une librairie écrite en C et C++: Tesseract. Elle a été développée au départ Hewlett-Packard qui au final la rendu open source pour arriver dans les mains de… Google!
C’est assez pour la petite histoire, ce qui nous intéresse c’est de compiler Tesseract pour l’iPhone afin que la librairie soit utilisable dans les applications. Et cela grâce à de la cross compilation. En bref, le SDK de l’iPhone fournissant des compilateurs C et C++ spécifiques pour lui, on va prendre les sources de la librairie, compiler Tesseract. Awesome, non?
Pour la compilation, on va utiliser l’excellent script shell de Robert Carlsen. Il faut vérifier que vous :
- êtes sous MacOS X. Oui, ceux qui ont l’iPhone SDK sous autre chose que MacOS, vous sortez :)
- avez installé XCode 3.2.4
- Enfin, il faut noter si vous avez installé libtiff sur votre système ou pas. Il faudra modifier le script shell en conséquence.
Voici la compilation de la librairie en étapes, inspirée par le billet de Robert:
- Obtenir les sources de tesseract avec un
svn checkout http://tesseract-ocr.googlecode.com/svn/trunk/ tesseract-ocr-read-only-
Copier le script shell disponible ici et le mettre dans un fichier build_fat.sh et mettre se fichier dans tesseract-ocr-read-only
-
Si vous avez libtiff installé, il faut modifier le script shell. Et oui la compilation de tesseract va se faire avec le moins de dépendances possibles, histoire de pouvoir l’installer sur l’iPhone sans avoir à installer dans notre cas, libtiff. Dans le script shell, sur les deux lignes ./configure, il faut ajouter le paramètre suivant _-with-libtiff=nil_pour que les deux lignes deviennent:
./configure --host=arm-apple-darwin -with-libtiff=nil
et
./configure -with-libtiff=nil
- Exécuter le script avec:
./build_fat.sh
- Boire un café.
Le résultat est dans le dossier outdir. Sous forme de librairies *.a que l’on peut importer sous XCode directement sous Frameworks.
Robert Carlsen ne s’est pas arreté en si bon chemin, puisqu’il a fait une application d’exemple pour l’iPhone pour que tout le monde puisse voir comment utiliser tesseract depuis du code Objective C. Cette application de démo, c’est Pocket OCR, disponible sur github.
Et le résultat?
Alors bien sûr, il faut pas s’attendre à des miracles! Tesseract extrait ce qu’il peut et comme il peut. En clair, il va être très fort avec les images qui représente la feuille blanche avec du texte dessus. Là, les résultats sont assez impressionants:
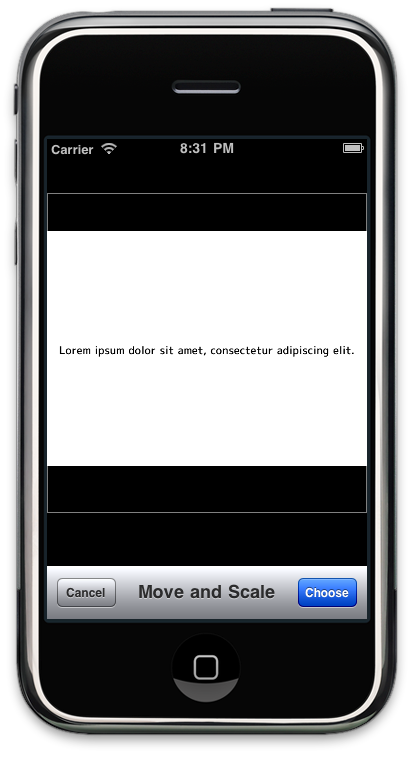
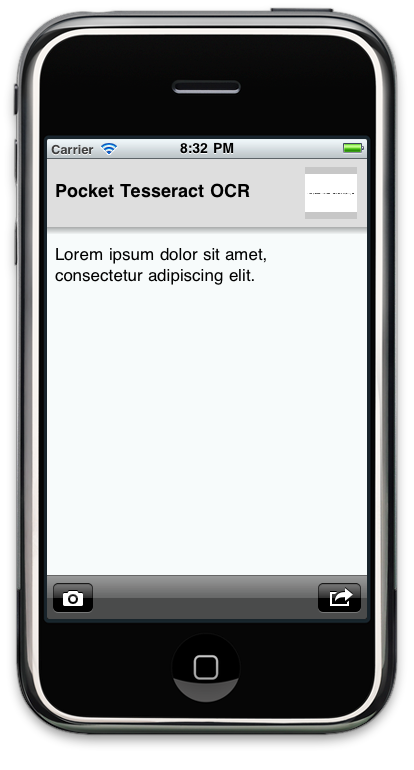
Par contre, si l’image contient des traces comme une photocopie mal faite ou que l’image est en couleur avec des différences de contrast, il ne faut pas s’attendre à des résultats parfaits, mais tesseract se débrouille pas mal:
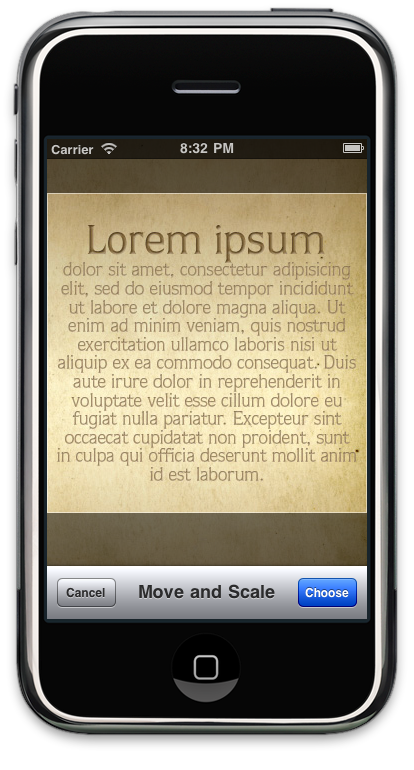

Dans tous les cas, le plus simple c’est d’essayer par soi-même sur le simulateur en prenant les images depuis la gallerie photo.

About Me
Oh yes! Another random tech blog about web technologies, programming and whatever goes randomly through my head. Think of this page as a little window of my mind. You are now belong to me! :o)
My name is David Fernandez. I'm web software engineer from Geneva, Switzerland and no, I don't eat cheese every day.